Judging what to carry in your AI toolkit
At an increasing pace, there’s a new AI skill, tool, model, or system-prompt directive/snippet promising to make your AI agent usage more effective. It can be hard to keep up with all the options available and the temptation to skip diligence is real. Most of these shiny objects vying for your attention are very cheap or free (open source), install in seconds, and the demo video and git repo README are plausible. Why not just install everything?
You could easily blitz through adopting many of these tools into your AI toolkit on the strength of some limited testing that looks plausibly good for the moment. In short order though, you will find yourself drifting into a quagmire of deteriorating results. You should apply care and a healthy amount of skepticism when assembling a probabilistic system which shares a precious resource (context) that can influence the quality of results.
Work like Context Length Alone Hurts LLM Performance Despite Perfect Retrieval backs up the lived experience of many developers assembling suites of AI tools: simply increasing how much is put in the context can degrade performance — so some prudence around what you add is warranted.


Every token you add to context is a token the model carries on every turn until that context is cleared. That carrying cost can snowball and actually make some models perform worse beyond certain thresholds, so it is important to measure whether you are actually achieving improved results at all, and what the carrying cost is for those results. Not only is there the here and now to consider, but how will you know if it is still a worthwhile or detrimental addition to your toolkit when a new model is released? We’re building a system of tools with interactions.
Manually evaluating every new potential improvement (think skill, MCP, hook, prompt snippet, etc) that you could add to your agentic workflow is rarely effective enough. A hands-on test still has value, but it is insufficient to assess risk and make sure the train stays on the tracks over time. Context changes especially can have unexpected interactions, and model capabilities will shift out from underneath you, potentially for better OR worse, over time.
Luckily, it has never been easier to automate a hands-off experiment to gather data on the effect of adopting an AI context modification, to get a sense of its carrying costs and effects for your codebase, your harness and your context.
I recommend you have a formal set of private evals in place to stand a chance of making steady improvements to any system over time, and in the case of AI and LLMs, especially to ensure you do not build a system that locks you in to one model with unknown amounts of risk. For the scope of this article though, let’s consider a first step up the ladder from flying mostly blind. Run an experiment!
Here is an example I recently kicked off for a project:
Example: Popular skills that claim token reduction
Two recent tools that popped on my radar are the caveman skill and the rtk skill.
Each of these tools aims to reduce token usage — but from opposite directions:
- caveman — a
SKILL.md(~5 KB) that prepends to your prompt and tells the model to communicate in compressed prose. Targets output tokens. - rtk — a small CLI proxy you wrap around
cargo,git,grep,cat, and friends. It emits a compressed view of those commands’ output. Targets input tokens.
Both have plausible stories for saving tokens, though caveman one look like inside joke ugh. Both have visible demos. caveman is prompt-context that condenses LLM output; rtk is rule file adjustment that causes tool calls to condense their output.
Measuring results against YOUR codebase
Rather than rely on a vibe-check or generalized benchmark provided by the tool provider (bias anyone?), I ran a matrix of tests against one of my actual rust codebases, using two real code changes pulled from git history:
- Tiny task — add a single 5-line unit test. One file read, one edit, one cargo invocation.
- Medium task — replay a real two-file refactor from history. ~50 KB of Rust across three files, two coordinated edits, the full 414-test cargo suite, many agent turns.
The experiment includes three models (claude opus-4.7, gpt-5.5, gpt-5.3-codex), three variants each (control, caveman, rtk), two classes of code changes. 18 runs total. The metric I hope each experiment reduces are the most costly billable ones: uncached input + output + reasoning tokens, compared to each model’s own control on the same task. I expect resulting code changes to be effectively similar/same.
My hypothesis going in was charitable: the medium task should give both tools room to work — more output to compress (caveman), more CLI tool output surface to wrap and condense (rtk).
The result
Out of 18 runs, only one challenger result beat its control. That was gpt-5.5 / caveman on the tiny task: −21% uncached+output tokens.
Every run produced functionally equivalent code: same diff shape, same cargo test pass count. So this isn’t a quality-versus-cost tradeoff.
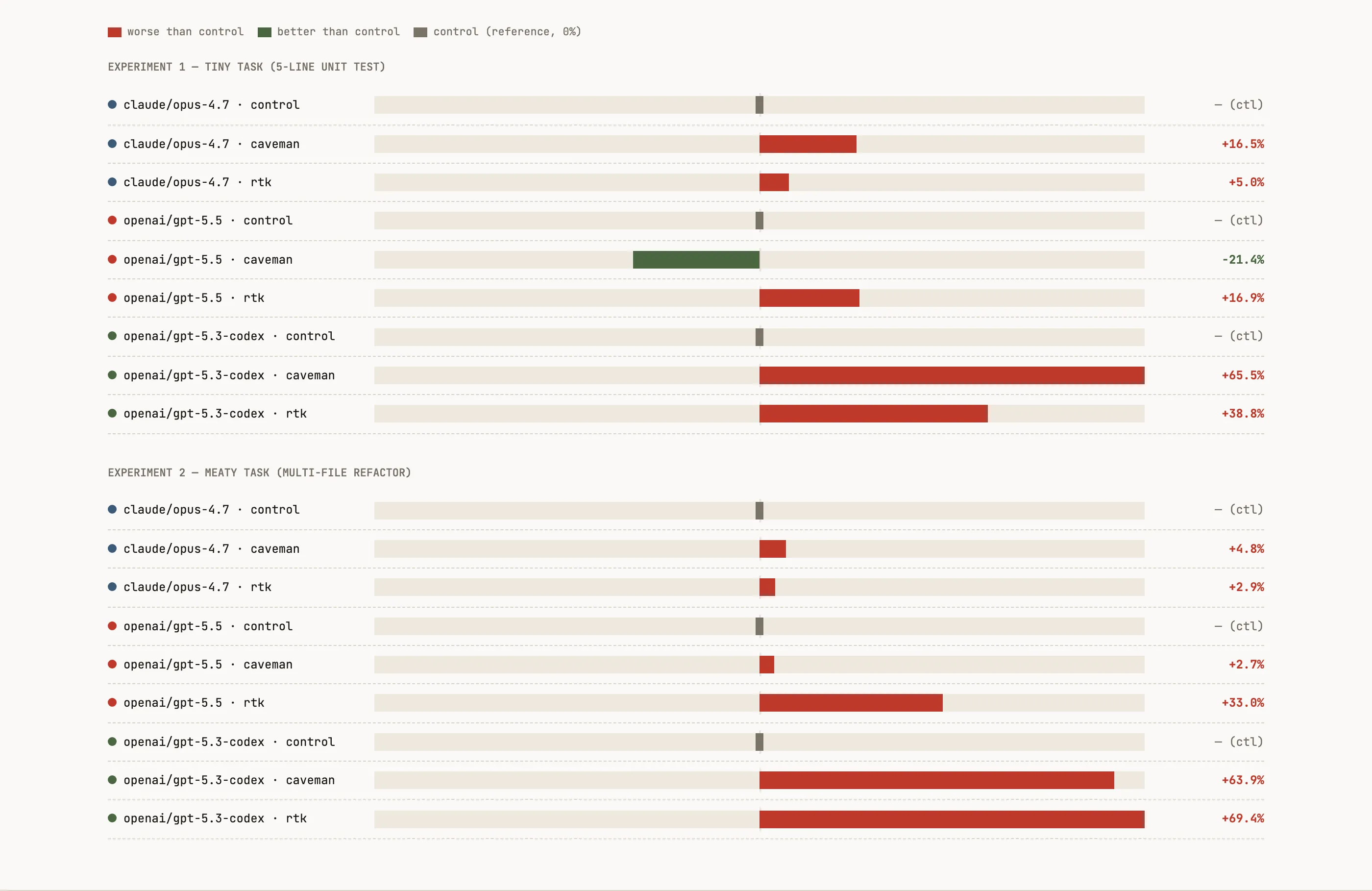
In the narrow sense, both tools do work as advertised. Caveman really does compress the human-readable message (570 → 41 bytes on one run). rtk really does compress loud command output when there is loud command output. The advertised effect is real, but neither was particularly effective at improving results in this particular codebase for these 2 representative changes, and thus, to me is not worth the carrying cost/risk. Looking deeper, I don’t do a lot of interactive turns (where caveman would have more of a visible effect), nor encounter a lot of errors or extraneous output (where rtk would have a greater impact), so it makes sense I’m not seeing much benefit here.
Takeaways
We’re already seeing a deluge of well-intentioned context modifiers (prompts and snippets, skills, MCPs, etc) that look like clear wins in general benchmarks or one-off examples, but don’t hold up when you assess them against your harness, your models, and your codebase. The easy dopamine hit is to install everything — and that’s short-sighted. If you want your dev loop to reliably get faster and more effective, you have to do the work to know what’s actually helping.
Be deliberate about what you adopt, measuring actual effect in your harness/dev loop, otherwise you are just rolling the dice.